We first present a few examples, insisting on the functional aspect of the language. Then, we formalize an extremely small subset of the language, which, surprisingly, contains in itself the essence of ML. Last, we show how to derive other constructs remaining in core ML whenever possible, or making small extensions when necessary.
Core ML is a small functional language. This means that functions are taken seriously, eg. they can be passed as arguments to other functions or returned as results. We also say that functions are first-class values.
In principle, the notion of a function relates as closely as possible to the one that can be found in mathematics. However, there are also important differences, because objects manipulated by programs are always countable (and finite in practice). In fact, core ML is based on the lambda-calculus, which has been invented by Church to model computation.
Syntactically, expressions of the lambda-calculus (written with letter a) are of three possible forms: variables x, which are given as elements of a countable set, functions λ x. a, or applications a1 a2. In addition, core ML has a distinguished construction let x = a1 in a2 used to bind an expression a1 to a variable x within an expression a2 (this construction is also used to introduce polymorphism, as we will see below). Furthermore, the language ML comes with primitive values, such as integers, floats, strings, etc. (written with letter c) and functions over these values.
Finally, a program is composed of a sequence of sentences that can
optionally be separated by double semi-colon “;;”.
A sentence is a single expression or the binding, written let x = a, of an
expression a to a variable x.
In normal mode, programs can be written in one or more files, separately
compiled, and linked together to form an executable machine code (see
Section 4.1.1). However, in the core language, we
may assume that all sentences are written in a single file; furthermore, we
may replace ;; by in turning the sequence of sentences into a
single expression. The language OCaml also offers an interactive loop in
which sentences entered by the user are compiled and executed immediately;
then, their results are printed on the terminal.
We use the interactive mode to illustrate most of the examples. The input
sentences are closed with a double semi-colons “;;”.
All programs and the output of the interpreter (when useful)
are displayed in a pink background. Input is marked with a vertical bar on
the left margin, usually in green, except for incorrect programs that that
uses a red mark. Here is an example.
Some larger examples, called implementation notes, are delimited
by horizontal braces as illustrated right below:
Implementation notes are delimited as this one. They contain explanations in English (not in OCaml comments) and several OCaml phrases.
|
All phrases of a
note belong to the same file (this one belong to README) and are meant
to be compiled (rather than interpreted).
As an example, here are a couple of phrases evaluated in the interactive loop.
| ||||
| ||||
| ||||
| ||||
|
The execution of the first phrase prints the string "Hello\n"unit. The
evaluation of the second phrase binds the intermediate result of the
evaluation of the expression 4.0 * atan 1.0, that is the float
3.14..., to the variable pi. This execution does not produce any
output; the system only prints the type information and the value that
is bound to pi. The last phrase defines a function that takes a
parameter x and returns the product of x and itself. Because of
the type of the binary primitive operation *., which is
float -> float -> float, the system infers that both x
and the the result square x must be of type float.
A mismatch between types, which often reveals a programmer's error, is
detected and reported:
| |||
|
Function definitions may be recursive, provided this is requested explicitly,
using the keyword rec:
| |||
| |||
| |||
|
Functions can be passed to other functions as argument, or received as results, leading to higher-functions also called functionals. For instance, the composition of two functions can be defined exactly as in mathematics:
| |||
|
The best illustration OCaml of the power of functions might be the function “power” itself!
| |||
|
Here, the expression (fun x -> x) is the anonymous identity
function.
Extending the parallel with mathematics, we may define the derivative of an
arbitrary function f. Since we use numerical rather than formal
computation, the derivative is parameterized by the increment step
dx:
| |||
|
Then, the third derivative sin''' of the sinus function can be
obtained by computing the cubic power of the derivative function and
applying it to the sinus function. Last, we calculate its value for the real
pi.
| |||
|
This capability of functions to manipulate other functions as one would do in mathematics is almost unlimited... modulo the running time and the rounding errors.
Before continuing with more features of OCaml, let us see how a very simple subset of the language can be formalized.
In general, when giving a formal presentation of a language, we tend to keep the number of constructs small by factoring similar constructs as much as possible and explaining derived constructs by means of simple translations, such as syntactic sugar.
For instance, in the core language, we can omit phrases. That is, we transform sequences of bindings such as let x1 = a1;; let x2 = a2;; a into expressions of the form let x1 = a1 in let x2 = a2 in a. Similarly, numbers, strings, but also lists, pairs, etc. as well as operations on those values can all be treated as constants and applications of constants to values.
Formally, we assume a collection of constants c ∈ C that are partitioned into constructors C ∈ C+ and primitives f ∈ C−. Constants also come with an arity, that is, we assume a mapping arity from C to IN. For instance, integers and booleans are constructors of arity 0, pair is a constructor of arity 2, arithmetic operations, such as + or × are primitives of arity 2, and not is a primitive of arity 1. Intuitively, constructors are passive: they may take arguments, but should ignore their shape and simply build up larger values with their arguments embedded. On the opposite, primitives are active: they may examine the shape of their arguments, operate on inner embedded values, and transform them. This difference between constants and primitives will appear more clearly below, when we define their semantics. In summary, the syntax of expressions is given below:
| a ::= |
| ∣ c ∣ let x = a in a c ::= |
| ∣ |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
Expressions can be represented in OCaml by their
abstract-syntax trees, which are elements of the following data-type
expr:
|
For convenience, we define auxiliary functions to build constants.
|
Here is a sample program.
|
Of course, a full implementation should also provide a lexer and a parser,
so that the expression e could be entered using the concrete syntax
(λ x. x * x) ((λ x. x+1) 2) and be automatically transformed
into the abstract syntax tree above.
Giving the syntax of a programming language is a prerequisite to the definition of the language, but does not define the language itself. The syntax of a language describes the set of sentences that are well-formed expressions and programs that are acceptable inputs. However, the syntax of the language does not determine how these expressions are to be computed, nor what they mean. For that purpose, we need to define the semantics of the language.
(As a counter example, if one uses a sample of programs only as a pool of inputs to experiment with some pretty printing tool, it does not make sense to talk about the semantics of these programs.)
There are two main approaches to defining the semantics of programming languages: the simplest, more intuitive way is to give an operational semantics, which amounts to describing the computation process. It relates programs —as syntactic objects— between one another, closely following the evaluation steps. Usually, this models rather fairly the evaluation of programs on real computers. This level of description is both appropriate and convenient to prove properties about the evaluation, such as confluence or type soundness. However, it also contains many low-level details that makes other kinds of properties harder to prove. This approach is somehow too concrete —it is sometimes said to be “too syntactic”. In particular, it does not explain well what programs really are.
The alternative is to give a denotational semantics of programs. This amounts to building a mathematical structure whose objects, called domains, are used to represent the meanings of programs: every program is then mapped to one of these objects. The denotational semantics is much more abstract. In principle, it should not use any reference to the syntax of programs, not even to their evaluation process. However, it is often difficult to build the mathematical domains that are used as the meanings of programs. In return, this semantics may allow to prove difficult properties in an extremely concise way.
The denotational and operational approaches to semantics are actually complementary. Hereafter, we only consider operational semantics, because we will focus on the evaluation process and its correctness.
In general, operational semantics relates programs to answers describing the result of their evaluation. Values are the subset of answers expected from normal evaluations.
A particular case of operational semantics is called a reduction semantics. Here, answers are a subset of programs and the semantic relation is defined as the transitive closure of a small-step internal binary relation (called reduction) between programs.
The latter is often called small-step style of operational semantics, sometimes also called Structural Operational Semantics [61]. The former is big-step style, sometimes also called Natural Semantics [39].
The call-by-value reduction semantics for ML is defined as follows: values are either functions, constructed values, or partially applied constants; a constructed value is a constructor applied to as many values as the arity of the constructor; a partially applied constant is either a primitive or a constructor applied to fewer values than the arity of the constant. This is summarized below, writing v for values:
| v ::= λ x. a ∣ |
| ∣ |
| k < n | ||||||||||||||||||||||||||||||||||||||
In fact, a partially applied constant cn v1 … vk behaves as the function λ xk+1. …λ xn. ck v1 … vk xk+1 … xn, with k<n. Indeed, it is a value.
Since values are subsets of programs, they can be characterized by
a predicate evaluated defined on expressions:
|
The small-step reduction is defined by a set of redexes and is closed by congruence with respect to evaluations contexts.
Redexes describe the reduction at the place where it occurs; they are the heart of the reduction semantics:
|
Redexes of the latter form, which describe how to reduce primitives, are also called delta rules. We write δ for the union ∪f ∈ C− (δf). For instance, the rule (δ+) is the relation {(p + q, p+q) ∣ p, q ∈ IN} where n is the constant representing the integer n.
Redexes are partial functions from programs to programs. Hence, they can be
represented as OCaml functions, raising an exception Reduce when there
are applied to values outside of their domain.
The δ-rules can be implemented straightforwardly.
|
The union of partial function (with priority on the right) is
|
The δ-reduction is thus:
|
To implement (βv), we first need an auxiliary function that substitutes a variable for a value in a term. Since the expression to be substituted will always be a value, hence closed, we do not have to perform α-conversion to avoid variable capture.
|
Then beta is straightforward:
|
Finally, top reduction is
|
The evaluation contexts E describe the occurrences inside programs where the reduction may actually occur. In general, a (one-hole) context is an expression with a hole —which can be seen as a distinguished constant, written [·]— occurring exactly once. For instance, λ x. x [·] is a context. Evaluation contexts are contexts where the hole can only occur at some admissible positions that often described by a grammar. For ML, the (call-by-value) evaluation contexts are:
| E ::= [·] ∣ E a ∣ v E ∣ let x = E in a |
We write E[a] the term obtained by filling the expression a in the evaluation context E (or in other words by replacing the constant [·] by the expression a).
Finally, the small-step reduction is the closure of redexes by the congruence rule:
| if a → a' then E [a] → E [a']. |
The evaluation relation is then the transitive closure →* of the small step reduction →. Note that values are irreducible, indeed.
There are several ways to treat evaluation contexts in practice. The most standard solution is not to represent them, ie. to represent them as evaluation contexts of the host language, using its run-time stack. Typically, an evaluator would be defined as follows:
|
The function eval visits the tree top-down. On the descent it
evaluates all subterms that are not values in the order prescribed by the
evaluation contexts; before ascent, it replaces subtrees bu their evaluated
forms. If this succeeds it recursively evaluates the reduct; otherwise, it
simply returns the resulting expression.
This algorithm is efficient, since the input term is scanned only once, from the root to the leaves, and reduced from the leaves to the root. However, this optimized implementation is not a straightforward implementation of the reduction semantics.
If efficiency is not an issue, the step-by-step reduction can be recovered by a slight change to this algorithm, stopping reduction after each step.
|
Here, contexts are still implicit, and redexes are immediately reduced and
put back into their evaluation context. However, the eval_step function
can easily be decomposed into three operations: eval_context that
returns an evaluation context and a term, the reduction per say, and the
reconstruction of the result by filling the result of the reduction back
into the evaluation context. The simplest representation of contexts is to
view them as functions form terms to terms as follows:
|
Then, the following function split a term into a pair of an evaluation context and a term.
|
Finally, it the one-step reduction rewrites the term as a pair E [a] of an evaluation context E and a term t, apply top reduces the term a to a', and returns E [a], exactly as the formal specification.
|
The reduction function is obtain from the one-step reduction by iterating the process until no more reduction applies.
|
This implementation of reduction closely follows the formal definition. Of course, it is less efficient the direct implementation. Exercise 1 presents yet another solution that combines small step reduction with an efficient implementation.
| let x = v in a → (λ x. a) v |
|
| |||
|
In fact, it is more convenient to hold contexts by their hole—where reduction happens. To this aim, we represent them upside-down, following Huet's notion of zippers [32]. Zippers are a systematic and efficient way of representing every step while walking along a tree. Informally, the zipper is closed when at the top of the tree; walking down the tree will open up the top of the zipper, turning the top of the tree into backward-pointers so that the tree can be rebuilt when walking back up, after some of the subtrees might have been changed.
Actually, the zipper definition can be read from the formal BNF definition of evaluations contexts:
| E ::= [·] ∣ E a ∣ v E ∣ let x = E in a |
The OCaml definition is:
|
The left argument of constructor AppR is always a value. A value is a
expression of a certain form. However, the type system cannot enfore this
invariant. For sake of efficiency, values also carry their
arity, which is the number of arguments a value must be applied to before
any reduction may occur. For instance, a constant of arity k is a value of
arity k. A function is a value of arity 1. Hence, a fully applied
contructor such as 1 will be given an strictly positive arity, eg. 1.
Note that the type context is linear, in the sense that constructors have
at more one context subterm. This leads to two opposite representations of
contexts. The naive representation of context let x = [·] a2 in a3
is LetL (x, AppL (Top, a2)), a3).
However, we shall represent them upside-down by the term
AppL (LetL (x, Top, a3), a2), following the idea of zippers —this
justifies our choice of Top rather than Hole for the empty
context. This should read “a context where the hole is below the left
branch of an application node whose right branch is a3 and
which is itself (the left branch of) a binding of x whose body is a2
and which is itself at the top”.
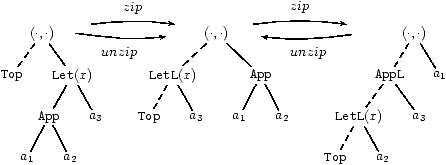
A term a0 can usually be decomposed as a one hole context E [a] in many ways if we do not impose that a is a reducible. For instance, taking (a1 a2) a3, allows the following decompositions
|
(The last decompistion is correct only when a1 is a value.) These decompositions can be described by a pair whose left-hand side is the context and whose right-hand side is the term to be placed in the hole of the context:
| Top, Let (x, App (a1, a2), a3) LetL (x, Top, a3), App (a1, a2) AppL (LetL (Top, a2), a3), a1 AppR ((k, a1), LetL (Top, a3)) a2 |
They can also be represented graphically:
|
As shown in the graph, the different decompositions can be obtained by zipping (push some of the term structure inside the context) or unzipping (popping the structure from the context back to the term). This allows a simple change of focus, and efficient exploration and transformation of the region (both up the context and down the term) at the junction.
Give a program context_fill of type context * expr -> expr that
takes a decomposition (E, a) and returns the expression E[a].
Define a function decompose_down of type
context * expr -> context * expr that given a decomposition (E, a)
searches for a sub-context E' of E in evaluation position and the
residual term a' at that position and returns the decomposition E[E'[·]], a' or it raises the exception Value k if a is a
value of arity k in evaluation position or the exception Error if
a is an error (irreducible but not a value) in evaluation position.
Starting with (Top, a), we may find the first position (E0, a0) where reduction may occur and then top-reduce a0 into a0'. After reduction, one wish to find the next evaluation position, say (En, an) given (En−1, a'n−1) and knowing that En−1 is evaluation context but a'n−1 may know be a value.
Define an auxilliary function decompose_up that takes an integer
k and a decomposition (c, v) where v is a value of arity k and find
a decomposition of c [v] or raises the exception
Not_found when non exists. The integer k represents the number of
left applications that may be blindly unfolded before decomposing down.
Define a function decompose that takes a context pair (E, a) and
finds a decomposition of E [a]. It raises the exception
Not_found if no decomposition exists and the exception Error if
an irreducible term is found in evaluation position.
Finally, define the eval_step reduction, and check the evaluation
steps of the program e given above and recover the function
reduce of type expr -> expr that reduces an expression to a
value.
Write a pretty printer for expressions and contexts, and use it to trace evaluation steps, automatically.
Then, it suffices to use the OCaml toplevel tracing capability for functions
decompose and reduce_in to obtain a trace of evaluation steps
(in fact, since the result of one function is immediately passed to the
other, it suffices to trace one of them, or to skip output of traces).
| |||
|
The strategy we gave is call-by-value: the rule (βv) only applies when the argument of the application has been reduced to value. Another simple reduction strategy is call-by-name. Here, applications are reduced before the arguments. To obtain a call-by-name strategy, rules (βv) and (Letv) need to be replaced by more general versions that allows the arguments to be arbitrary expressions (in this case, the substitution operation must carefully avoid variable capture).
|
Simultaneously, we must restrict evaluation contexts to prevent reductions of the arguments before the reduction of the application itself; actually, it suffices to remove v E and let x = E in a from evaluations contexts.
| En ::= [·] ∣ En a |
There is, however, a slight difficulty: the above definition of evaluation contexts does not work for constants, since δ-rules expect their arguments to be reduced. If all primitives are strict in their arguments, their arguments could still be evaluated first, then we can add the following evaluations contexts:
| En ::= … ∣ (fn v1 … vk−1 Ek ak+1 ... an) |
However, in a call-by-name semantics, one may wish to have constants such
as fst that only forces the evaluation of the top-structure of the
terms. This is is slightly more difficult to model.
|
As illustrated in this example, call-by-name may duplicate some computations. As a result, it is not often used in programming languages. Instead, Haskell and other lazy languages use a call-by-need or lazy evaluation strategy: as with call-by-name, arguments are not evaluated prior to applications, and, as with call-by-value, the evaluation is shared between all uses of the same argument. However, call-by-need semantics are slightly more complicated to formalize than call-by-value and call-by-name, because of the formalization of sharing. They are quite simple to implement though, using a reference to ensure sharing and closures to delay evaluations until they are really needed. Then, the closure contained in the reference is evaluated and the result is stored in the reference for further uses of the argument.
Remark that the call-by-value evaluation that we have defined is deterministic by construction. According to the definition of the evaluation contexts, there is at most one evaluation context E such that a is of the form E[a']. So, if the evaluation of a program a reaches program a∗, then there is a unique sequence a = a0 → a1 → … an = a∗. Reduction may become non-deterministic by a simple change in the definition of evaluation contexts. (For instance, taking all possible contexts as evaluations context would allow the reduction to occur anywhere.)
Moreover, reduction may be left non-deterministic on purpose; this is usually done to ease compiler optimizations, but at the expense of semantic ambiguities that the programmer must then carefully avoid. That is, when the order of evaluation does matter, the programmer has to use a construction that enforces the evaluation in the right order.
In OCaml, for instance, the relation is non-deterministic: the order of evaluation of an application is not specified, ie. the evaluation contexts are:
| E ::= [·]∣ E a ∣ a |
| ] E ⇑ even if a is not reduced ∣ let x = E in a | ||||||||||||||||
When the reduction is not deterministic, the result of evaluation may still be deterministic if the reduction is Church-Rosser. A reduction relation has the Church-Rosser property, if for any expression a that reduces both to a' or a'' (following different branches) there exists an expression a''' such that both a' and a'' can in turn be reduced to a'''. (However, if the language has side effects, Church Rosser property will very unlikely be satisfied).
For the (deterministic) call-by-value semantics of ML, the evaluation of a program a can follow one of the following patterns:
| a → a1 → … | ⎧ ⎪ ⎨ ⎪ ⎩ |
|
Normal evaluation terminates, and the result is a value. Erroneous evaluation also terminates, but the result is an expression that is not a value. This models the situation when the evaluator would abort in the middle of the evaluation of a program. Last, evaluation may also proceed forever.
The type system will prevent run-time errors. That is, evaluation of well-typed programs will never get “stuck”. However, the type system will not prevent programs from looping. Indeed, for a general purpose language to be interesting, it must be Turing complete, and as a result the termination problem for admissible programs cannot be decidable. Moreover, some non-terminating programs are in fact quite useful. For example, an operating system is a program that should run forever, and one is usually unhappy when it terminates —by accident.
In the evaluator, errors can be observed as being irreducible programs that
are not values. For instance, we can check that e evaluates to a
value, while (λ x. y) 1 does not reduce to a value.
|
Conversely, termination cannot be observed. (One can only suspect non-termination.)
The advantage of the reduction semantics is its conciseness and modularity. However, one drawback of is its limitation to cases where values are a subset of programs. In some cases, it is simpler to let values differ from programs. In such cases, the reduction semantics does not make sense, and one must relates programs to answers in a simple “big” step.
A typical example of use of big-step semantics is when programs are evaluated in an environment e that binds variables (eg. free variables occurring in the term to be evaluated) to values. Hence the evaluation relation is a triple ρ ||− a ⇒ r that should be read “In the evaluation environment e the program a evaluates to the answer r.”
Values are partially applied constants, totally applied constructors as
before, or closures. A closure is a pair written ⟨ λ x. a, e⟩ of
a function and an environment (in which the function should be
executed). Finally, answers are values or plus a
distinguished answer error.
|
The big-step evaluation relation (natural semantics) is often described via inference rules.
| P1 ... Pn |
| C |
is composed of premises P1, …Pn and a conclusion C and should be read as the implication: P1 ∧ … Pn ⇒ C; the set of premises may be empty, in which case the inference rule is an axiom C.
The inference rules for the big-step operational semantics of Core ML are described in figure 1.1. For simplicity, we give only the rules for constants of arity 1. As for the reduction, we assume given an evaluation relation for primitives.
|
Rules can be classified into 3 categories:
Note that error propagation rules play an important role, since they define the evaluation strategy. For instance, the combination of rules Eval-App-Error-Left and Eval-App-Error-Right states that the function must be evaluated before the argument in an application. Thus, the burden of writing error rules cannot be avoided. As a result, the big-step operation semantics is much more verbose than the small-step one. In fact, big-step style fails to share common patterns: for instance, the reduction of the evaluation of the arguments of constants and of the arguments of functions are similar, but they must be duplicated because the intermediate state v1 v2 is not well-formed —it is not yet value, but no more an expression!
Another problem with the big-step operational semantics is that it cannot describe properties of diverging programs, for which there is not v such that ρ ||− a ⇒ v. Furthermore, this situation is not a characteristic of diverging programs, since it could result from missing error rules.
The usual solution is to complement the evaluation relation by a diverging predicate ρ ||− a ⇑.
The big-step evaluation semantics suggests another more direct implementation of an interpreter.
| type env = (string * value) list and value = | Closure of var * expr * env | Constant of constant * value list |
To keep closer to the evaluation rules, we represent errors explicitly
using the following answer datatype. In practice, one would take
avantage of exceptions making value be the default answer
and Error be an exception instead. The construction Error
would also take an argument to report the cause of error.
| type answer = Error | Value of value;; |
Next comes delta rules, which abstract over the set of primitives.
| let val_int u = Value (Constant ({name = Int u; arity = 0; constr = true}, []));; let delta c l = match c.name, l with | Name "+", [ Constant ({name=Int u}, []); Constant ({name=Int v}, [])] -> val_int (u + v) | Name "*", [ Constant ({name=Int u}, []); Constant ({name=Int v}, [])] -> val_int (u * v) | _ -> Error;; |
Finally, the core of the evaluation.
| let get x env = try Value (List.assoc x env) with Not_found -> Error;; let rec eval env = function | Var x -> get x env | Const c -> Value (Constant (c, [])) | Fun (x, a) -> Value (Closure (x, a, env)) | Let (x, a1, a2) -> begin match eval env a1 with | Value v1 -> eval ((x, v1)::env) a2 | Error -> Error end | App (a1, a2) -> begin match eval env a1 with | Value v1 -> begin match v1, eval env a2 with | Constant (c, l), Value v2 -> let k = List.length l + 1 in if c.arity < k then Error else if c.arity > k then Value (Constant (c, v2::l)) else if c.constr then Value (Constant (c, v2::l)) else delta c (v2::l) | Closure (x, e, env0), Value v2 -> eval ((x, v2) :: env0) e | _, Error -> Error end | Error -> Error end | _ -> Error ;; |
Note that treatment of errors in the big-step semantics explicitly specifies a left-to-right evaluation order, which we have carefully reflected in the implementation. (In particular, if a1 diverges and a2 evaluates to an error, then a1 a2 diverges.)
| eval [] e;; |
| - : answer = Value (Constant ({name = Int 9; constr = true; arity = 0}, [])) |
While the big-step semantics is less interesting (because less precise) than the small-steps semantics in theory, its implementation is intuitive, simple and lead to very efficient code.
This seems to be a counter-example of practice meeting theory, but actually it is not: the big-step implementation could also be seen as efficient implementation of the small-step semantics obtained by (very aggressive) program transformations.
Also, the non modularity of the big-step semantics remains a serious drawback in practice. In conclusion, although the most commonly preferred the big-step semantics is not always the best choice in practice.
We start with the less expressive but simpler static semantics called simple types. We present the typing rules, explain type inference, unification, and only then we shall introduce polymorphism. We close this section with a discussion about recursion.
Expressions of Core ML are untyped —they do not mention types. However, as we have seen, some expressions do not make sense. These are expressions that after a finite number of reduction steps would be stuck, ie. irreducible while not being a value. This happens, for instance when a constant of arity 0, say integer 2, is applied, say to 1. To prevent this situation from happening one must rule out not only stuck programs, but also all programs reducing to stuck programs, that is a large class of programs. Since deciding whether a program could get stuck during evaluation is equivalent to evaluation itself, which is undecidable, to be safe, one must accept to also rule out other programs that would behave correctly.
Types are a powerful tool to classify programs such that well-typed programs cannot get stuck during evaluations. Intuitively, types abstract over from the internal behavior of expressions, remembering only the shape (types) of other expression (integers, booleans, functions from integers to integers, etc.), that can be passed to them as arguments or returned as results.
We assume given a denumerable set of type symbols g ∈ G. Each symbol should be given with a fixed arity. We write gn to mean that g is of arity n, but we often leave the arity implicit. The set of types is defined by the following grammar.
| τ ::= α ∣ gn (τ1, … τn) |
Indeed, functional types, ie. the type of functions play a crucial role. Thus, we assume that there is a distinguished type symbol of arity 2, the right arrow “→” in G; we also write τ → τ' for → (τ, τ'). We write ftv(τ) the set of type variables occurring in τ.
Types of programs are given under typing assumptions, also called typing environments, which are partial mappings from program variables and constants to types. We use letter z for either a variable x or a constant c. We write ∅ for the empty typing environment and A, x : τ for the function that behaves as A except for x that is mapped to τ (whether or not x is in the domain of A). We also assume given an environment A0 that assigns types to constants. The typing of programs is represented by a ternary relation, written A ⊢ a : τ and called typing judgments, between type environments A, programs a, and types τ. We summarize all these definitions (expanding the arrow types) in figure 1.2.
|
Typing judgments are defined as the smallest relation satisfying the inference rules of figure 1.3.
|
(See 1.3.3 for an introduction to inference rules)
Closed programs are typed the initial environment A0. Of course, we must assume that the type assumptions for constants are consistent with their arities. This is the following asumption.
Type soundness asserts that well-typed programs cannot go wrong. This actually results from two stronger properties, that (1) reduction preserves typings, and (2) well-typed programs that are not values can be further reduced. Of course, those results can be only proved if the types of constants and their semantics (ie. their associated delta-rules) are chosen accordingly.
To formalize soundness properties it is convenient to define a relation ≤ on programs to mean the preservation of typings:
| (a ≤ a') ⇔∀ (A, τ) (A ⊢ a : τ ⇒ A ⊢ a' : τ) |
The relation ≤ relates the set of typings of two programs programs, regardless of their dynamic properties.
The preservation of typings can then be stated as ≤ being a smaller relation than reduction. Of course, we must make the following assumptions enforcing consistency between the types of constants and their semantics:
|
We have seen that well-typed terms cannot get stuck, but can we check whether a given term is well-typed? This is the role of type inference. Moreover, type inference will characterize all types that can be assigned to a well-typed term.
The problem of type inference is: given a type environment A, a term a, and a type τ, find all substitutions θ such that θ(A) ⊢ a : θ(τ). A solution θ is a principal solution of a problem P if all other solutions are instances of θ, ie. are of the form θ' ∘ θ for some substitution θ'.
Moreover, there exists an algorithm that, given any type-inference problem, either succeeds and returns a principal solution or fails if there is no solution.
Usually, the initial type environment A0 is closed, ie. it has no free type variables. Hence, finding a principal type for a closed program a in the initial type environment is the same problem as finding a principal solution to the type inference problem (A, a, α).
In the rest of this section, we show how to compute principal solutions to type inference problems. We first introduce a notation A ▷ a : τ for type inference problems. Note that A ▷ a : τ does not mean A ⊢ a : τ. The former is a (notation for a) triple while the latter is the assertion that some property holds for this triple. A substitution θ is a solution to the type inference problem A ▷ a : τ if θ(A) ⊢ a : θ(τ). A key property of type inference problems is that their set of solutions are closed by instantiation (ie. left-composition with an arbitrary substitution). This results from a similar property for typing judgments: if A ⊢ a : τ, then θ(A) ⊢ a : θ(τ) for any substitution θ.
This property allows to treat type inference problems as constraint problems, which are a generalization of unification problems. The constraint problems of interest here, written with letter U, are of one the following form.
| U ::= |
| ∣ |
| ∣ U ∧ U ∣ ∃ α. U ∣ ⊥ ∣ T | ||||||||||||||||||||||||||||||||||||||||||
The two first cases are type inference problems and multi-equations (unification problems); the other forms are conjunctions of constraint problems, and the existential quantification problem. For convenience, we also introduce a trivial problem T and an unsolvable problem ⊥, although these are definable.
It is convenient to identify constraint problems modulo the following equivalences, which obviously preserve the sets of solutions: the symbol ∧ is commutative and associative. The constraint problem ⊥ is absorbing and T is neutral for ∧, that is U ∧ ⊥ = ⊥ and U ∧ T = T. We also treat ∃ α. U modulo renaming of bound variables, and extrusion of quantifiers; that is, if α is not free in U then ∃ α'. U = ∃ α. U [α' ← α] and U ∧ ∃ α. U' = ∃ α. (U ∧ U').
|
Type inference can be implemented by a system of rewriting rules that reduces any type inference problem to a unification problem (a constraint problem that does not constraint any type inference problem). In turns, type inference problems can then be resolved using standard algorithms (and also given by rewriting rules on unificands). Rewriting rules on unificands are written either U → U' (or
| U |
| U' |
) and should be read “U rewrites to U'”. Each rule should preserve the set of solutions, so as to be sound and complete.
The rules for type inference are given in figure 1.4. Applied in any order, they reduce any typing problem to a unification problem. (Indeed, every rule decomposes a type inference problem to smaller ones, where the size is measured by the height of the program expression.)
For Let-bindings, we can either treat them as syntactic sugar and the rule Let-Sugar or use the simplification rule derived from the rule Let-Mono:
|
Since they are infinitely many constants (they contain integers), we
represent the initial environment as a function that maps constants to
types. It raises the exception Free when the requested constant does
not exist.
We slightly differ from the formal presentation, by splitting bindings
for constants (here represented by the global function type_of_const)
and binding for variables (the only one remaining in type environments).
|
Type inference uses the function unify defined below to solved
unification problems.
|
As an example:
|
Normal forms for unification problems are ⊥, T, or ∃ α. U where each U is a conjunction of multi-equations and each multi-equation contains at most one non-variable term. (Such multi-equations are of the form α1 = … αn = τ or α= τ for short.) Most-general solutions can be obtained straightforwardly from normal forms (that are not ⊥).
The first step is to rearrange multi-equations of U into the conjunction α1 = τ1 ∧ … αn = τn such that a variable of αj never occurs in τi for i ≤ j. (Remark, that since U is in normal form, hence completely merged, variables α1, …αn are all distinct.) If no such ordering can be found, then there is a cycle and the problem has no solution. Otherwise, the composition (α1 ↦ τ1) ∘ … (αn ↦ τn) is a principal solution.
For instance, the unification problem (g1 → α1) → α1 = α2 → g2 can be reduced to the equivalent problem α1 = g2 ∧ α2 = (g1 → α1), which is in a solved form. Then, {α1 ↦ g2, α2 ↦ (g1 → g2)} is a most general solution.
|
The rules for unification are standard and described in figure 1.5. Each rule preserves the set of solutions. This set of rules implements the maximum sharing so as to avoid duplication of computations. Auxiliary variables are used for sharing: the rule Generalize allows to replace any occurrence of a subterm τ by a variable α and an additional equation α = τ. If it were applied alone, rule Generalize would reduce any unification problem into one that only contains small terms, ie. terms of size one.
In order to obtain maximum sharing, non-variable terms should never be copied. Hence, rule Decompose requires that one of the two terms to be decomposed is a small term—which is the one used to preserve sharing. In case neither one is a small term, rule Generalize can always be applied, so that eventually one of them will become a small term. Relaxing this constraint in the Decompose rule would still preserve the set of solutions, but it could result in unnecessarily duplication of terms.
Each of these rules except (the side condition of) the Cycle rule have a constant cost. Thus, to be efficient, checking that the Cycle rule does not apply should preferably be postponed to the end. Indeed, this can then be done efficiently, once for all, in linear time on the size of the whole system of equations.
Note that rules for solving unificands can be applied in any order. They will always produce the same result, and more or less as efficiently. However, in case of failure, the algorithm should also help the user and report intelligible type-error messages. Typically, the last typing problem that was simplified will be reported together with an unsolvable subset of the remaining unification problem. Therefore, error messages completely depend on the order in which type inference and unification problems are reduced. This is actually an important matter in practice and one should pick a strategy that will make error report more pertinent. However, there does not seem to be an agreement on a best strategy, so far.
Before we describe unification itself, we must consider the representation of types and unificands carefully. As we shall see below, the two definitions are interleaved: unificands are pointers between types, and types can be represented by short types (of height at most 1) whose leaves are variables constrained to be equal to some other types.
More precisely, a multi-equation in canonical form α1 = α2 = … τ can be represented as a chain of indirections α1 ↦ α2 ↦ … τ, where ↦ means “has the same canonical element as” and is implemented by a link (a pointer); the last term of the chain —a variable or a non-variable type— is the canonical element of all the elements of the chain. Of course, it is usually chosen arbitrarily. Conversely, a type τ can be represented by a variable α and an equation α = τ, ie. an indirection α ↦ τ.
A possible implementation for types in OCaml is:
|
The field mark of type texp is used to mark nodes during
recursive visits.
Variables are automatically created with different identities. This avoid dealing with extrusion of existential variables. We also number variables with integers, but just to simplify debugging (and reading) of type expressions.
|
A conjunction of constraint problems can be inlined in the graph representation of types. For instance, α1 = α2 → α2 ∧ α2 = τ can be represented as the graph α1 ↦ (α2 → α2) where α2 ↦ τ.
Non-canonical constraint problems do not need to be represented explicitly, because they are reduced immediately to canonical unificands (ie. they are implicitly represented in the control flow), or if non-solvable, an exception will be raised.
We define auxiliary functions that build types, allocate markers, cut off
chains of indirections (function repr), and access the representation
of a type (function desc).
|
We can now consider the implementation of unification itself. Remember that a type τ is represented by an equation α = τ, and conversely, only decomposed multi-equations are represented, concretely; other multi-equations are represented abstractly in the control stack.
Let us consider the unification of two terms (α1 = τ1) and
(α2 = τ2). If α1 and α2 are identical, then so must be
τ1 and τ2 and and the to equations, so the problem is already in
solved form. Otherwise, let us consider the multi-equation e equal to
α1 = α2 = τ1 = τ2. If τ1 is a variable then e
is effectively built by linking τ1 to τ2, and conversely if τ2
is a variable. In this case e is fully decomposed, and the unification
completed. Otherwise, e is equivalent by rule Decompose to the
conjunction of (α1 = α2 = τ2) and the equations ei's
resulting from the decomposition of τ1 = τ2. The former is
implemented by a link from α1 to α2. The later is implemented by
recursive calls to the function unify. In case τ1 and τ2 are
incompatible, then unification fails (rule Fail).
|
This does not check for cycles, which we do separately at the end.
|
For instance, the following unification problems
has only recursive solutions, which is detected by cycle;
| ||||||
|
So far, we have only considered simple types, which do not allow any form of polymorphism. This is often bothersome, since a function such as the identity λ x. x of type α → α should intuitively be applicable to any value. Indeed, binding the function to a name f, one could expect to be able to reuse it several times, and with different types, as in let f = λ x. x in f (λ x. (x + f 1)). However, this expression does not typecheck, since while any type τ can be chosen for α only one choice can be made for the whole program.
One of the most interesting features of ML is its simple yet expressive form of polymorphism. ML allows type scheme to be assigned to let-bound variables that are the carrier of ML polymorphism.
A type scheme is a pair written ∀ α. τ of a set of variables α and a type τ. We identify τ with the empty type scheme ∀ . τ. We use the letter σ to represent type schemes. An instance of a type scheme ∀ α. τ is a type of the form τ [α← τ'] obtained by a simultaneous substitution in τ of all quantified variables α by simple types τ' in τ. (Note that the notation τ [τ' ← α] is an abbreviation for (α↦ τ')(τ).)
Intuitively, a type scheme represents the set of all its instances. We write ftv(∀ α. τ) for the set of free types variables of ∀ α. τ, that is, ftv(τ)∖ α. We also lift the definition of free type variables to typings environments, by taking the free type variables of its co-domain:
| ftv(A) = |
| ftv(A(z)) |
The representation of type schemes is straightforward (although other representations are possible).
|
ftv_type that computes ftv(τ) for types
(as a slight modification to the function acyclic).
Write a (simple version of a) function type_instance taking type
scheme σ as argument and returning a type instance of σ obtained by
renaming and stripping off the bound variables of σ (you may assume that
σ is acyclic here).
Even if the input is acyclic, it is actually a graph, and may contain some sharing. It would thus be more efficient to preserve existing sharing during the copying. Write such a version.
So as to enable polymorphism, we introduce polymorphic bindings z : σ in typing contexts. Since we can see a type τ as trivial type scheme ∀ ∅. τ, we can assumes that all bindings are of the form z : σ. Thus, we change rule Var to:
|
Accordingly, the initial environment A0 may now contain type schemes rather that simple types. Polymorphism is also introduced in the environment by the rule for bindings, which should be revised as follows:
|
That is, the type τ found for the expression a bound to x must be generalized “as much as possible”, that is, with respect to all variables appearing in τ but not in the context A, before being used for the type of variable x in the expression a'.
Conversely, the rule for abstraction remains unchanged: λ-bound variables remain monomorphic.
In summary, the set of typing rules of ML is composed of rules Fun, App from figure 1.3 plus rules Var-Const and Let from above.
Type inference can also be extended to handle ML polymorphism. Replacing types by type schemes in typing contexts of inference problems does not present any difficulty. Then, the two rewriting I-Fun, I-App do not need to be changed. The rewriting rule I-Var can be easily be adjusted as follows, so as to constrain the type of a variable to be an instance of its declared type-scheme:
|
The Let rule requires a little more attention because there is a dependency between the left and right premises. One solution is to force the resolution of the typing problem related to the bound expression to a canonical form before simplifying the unificand.
|
where Û(α) is a principal solution of U.
The implementation of type inference with ML polymorphism is a
straightforward modification of type inference with simple types, once we
have the auxiliary functions. We have already defined type_instance to
be used for the implementation of the rule Var-Const. We also need a
function generalizable to compute
generalizable variables ftv(t) ∖ ftv(A) from a type environment
A and a type τ. The obvious implementation would compute ftv(τ) and ftv(A) separately, then compute their set-difference. Although
this could be easily implemented in linear type, we get a more efficient
(and simpler) implementation by performing the whole operation
simultaneously.
ftv_type so as to obtain a direct
implementation of generalizable variables.
A naive computation of generalizable variables will visit both the type and the environment. However, the environment may be large while all free variables of the type may be bound in the most recent part of the type environment (which also include the case when the type is ground). The computation of generalizable variables can be improved by first computing free variables of the type first and maintaining an upper bound of the number of free variables while visiting the environment, so that this visit can be interrupted as soon as all variables of t are already found to be bound in A.
A more significant improvement would be to maintained in the structure of
tenv the list of free variables that are not already free on the left.
Yet, it is possible to implement the computation of generalizable variables
without ever visiting A by maintaining a current level of freshness.
The level is incremented when entering a let-binding and decremented on
exiting; it is automatically assigned to every allocated variable; then
generalizable variables are those that are still of fresh level after the
weakening of levels due to unifications.
Finally, here is the type inference algorithm reviewed to take polymorphism into account:
|
So as to be Turing-complete, ML should allow a form of recursion. This is provided by the let rec f = λ x. a1 in a2 form, which allows f to appear in λ x. a1, recursively. The recursive expression λ x. a1 is restricted to functions because, in a call-by-value strategy, it is not well-defined for arbitrary expressions.
Rather than adding a new construct into the language, we can take advantage of the parameterization of the definition of the language by a set of primitives to introduce recursion by a new primitive fix of arity 2 and the following type:
| fix : ∀ α1, α2. ((α1 → α2) → α1 → α2) → α1 → α2 |
The semantics of fix is given then by its δ-rule:
| fix f v → f (fix f) v (δfix) |
Since fix is of arity 2, the expression (fix f) appearing on the right hand side of the rule (δfix) is a value and its evaluation is frozen until it appears in an application evaluation context. Thus, the evaluation must continue with the reduction of the external application of f. It is important that fix be of arity 2, so that fix computes the fix-point lazily. Otherwise, if fix were of arity 1 and came with the following δ-rule,
| fix f → f (fix f) |
the evaluation of fix f v would fall into an infinite loop (the active part is underlined):
| v → f ( |
| ) v → f (f ( |
| )) v → ... |
For convenience, we may use let rec f = λ x. a1 in a2 as syntactic sugar for let f = fix (λ f. λ x. a1) in a2.
| λ f'. (λ f. λ x. f' (f f) x) (λ f. λ x. f' (f f) x) |
The language OCaml allows mutually recursive definitions. For example,
| let rec f1 = λ x. a1 and f2 = λ x. a2 in a |
where f and f' can appear in both a and a'. This can be seen as an abbreviation for
|
This can be easily generalize to
| let rec f1 = λ x. a1 and … fn λ x. an in a |
| let rec f1 = λ x. a1 and f2 = λ x. a2 and f3 = λ x. a3 in a |
Since, the expression let rec f = λ x. a in a' is understood as let f = fix (λ f. λ x. a) in a', the function f is not polymorphic while typechecking the body λ x. a, since this occurs in the context λ f. [·] where f is λ-bound. Conversely, f may be be in a' (if the type of f allows) since those occurrences are Let-bound.
Polymorphic recursion refers to system that would allow f to be polymorphic in a' as well. Without restriction, type inference in these systems is not decidable. [28, 75].
By default, the ML type system does not allows recursive types (but it allows recursive datatype definitions —see Section 2.1.3). However, allowing recursive types is a simple extension. Indeed, OCaml uses this extension to assign recursive types to objects. The important properties of the type systems, including subject reduction and the existence of principal types, are preserved by this extension.
Indeed, type inference relies on unification, which naturally works on graphs, ie. possibly introducing cycles, which are later rejected. To make the type inference algorithm work with recursive types, it suffices to remove the occur check rule in the unification algorithm. Indeed, one must then be careful when manipulating and printing types, as they can be recursive.
As shown in exercise 8, page ??, the fix point combinator is not typable in ML without recursive types. Unsurprisingly, if recursive types are allows, the call-by-value fix-point combinator fix is definable in the language.
print_type
that can handle recursive types (for instance, they can be printed
as in OCaml, using as to alias types).
See also section 3.2.1 for uses of recursive types in object types.
Recursive types are thus rather easy to incorporate into the language. They
are quite powerful —they can type the fix-point— and also useful and
sometimes required, as is the case for object types. However, recursive
types are sometimes too powerful since they will often hide programmers'
errors. In particular, it will detect some common forms of errors, such as
missing or extra arguments very late (see exercise below for a hint). For
this reason, the default in the OCaml system is to reject recursive types
that do not involve an object type constructor in the recursion. However,
for purpose of expressiveness or experimentation, the user can explicitly
require unrestricted recursive types using the option -rectypes
at his own risk of late detection of some from of errors —but the system
remains safe, of course!
ML programs are untyped. Type inference finds most general types for programs. It would in fact be easy to instrument type inference, so that it simultaneously annotate every subterm with its type (and let-bounds with type schemes), thus transforming an untyped term into type terms.
Indeed, type terms are more informative than untyped terms, but they can still be ill-typed. Fortunately, it is usually easier to check typed terms than untyped terms for well-typedness. In particular, type checking does not need to “guess” types, hence it does not need first-order unification.
Both type inference and type checking are verifying well-typedness of programs with respect to a given type system. However, type inference assumes that terms are untyped, while type checking assumes that terms are typed. This does not mean that type checking is simpler than type inference. For instance, some type checking problems are undecidable [59]. Type checking and type inference could also be of the same level of difficulty, if type annotations are not sufficient. However, in general, type annotations may be enriched with more information so that type checking becomes easier. On the opposite, there is no other flexibility but the expressiveness of the type system to adjust the difficulty of type inference.
The approach of ML, which consists in starting with untyped terms, and later infer types is usually called a la Curry, and the other approach where types are present in terms from the beginning and only checked is called a la Church.
In general, type inference is preferred by programmers who are relieved from the burden of writing down all type annotations. However, explicit types are not just annotations to make type verification simpler, but also a useful tool in structuring programs: they play a role for documentation, enables modular programming and increase security. For instance, in ML, the module system on top of Core ML is explicitly typed.
Moreover, the difference between type inference and type checking is not always so obvious. Indeed, all nodes of the language carry implicit type information. For instance, there is no real difference between 1 and 1 : int. Furthermore, some explicit type annotations can also be hidden behind new constants… as we shall do below.
Reference books on the lambda calculus, which is at the core of ML are [6, 29]. Both include a discussion of the simply-typed lambda calculus. The reference article describing the ML polymorphism and its type inference algorithm, called W, is [16]. However, Mini-ML [14] is more often used as a starting point to further extensions. This also includes a description of type-inference. An efficient implementation of this algorithm is described in [63]. Of course, many other presentations can be found in the literature, sometimes with extensions.
Basic references on unification are [49, 31]. A good survey that also introduces the notion of existential unificands that we used in our presentation is [40].